Using the Builder
The PullNode Builder is a point-and-click tool that allows you to scrape data from any website without writing a single line of code. This guide will walk you through the process of creating your first scraper using the PullNode Builder.
Prerequisites
Before you start, you will need to have the PullNode browser extension installed. Follow the steps in the Adding the PullNode browser extension guide to install the extension.
Starting the Builder
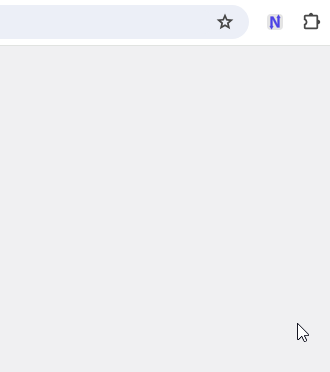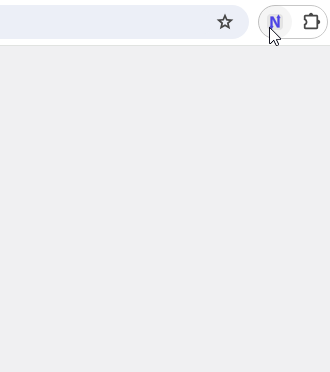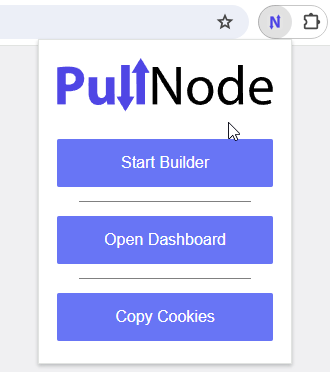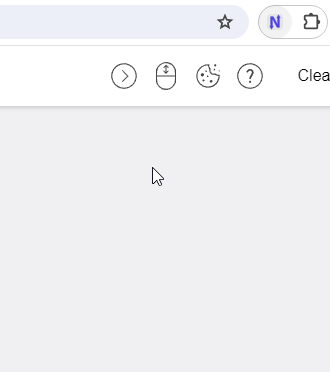
First, navigate to the website you want to scrape. Once you are on the website, click the PullNode extension icon in your browser's toolbar and select "Start Builder".
Adding properties
Once the Builder is open, you can start adding properties to your scraper. Properties are the data points you want to extract from the website. To add a property, simply click on the green + button, then click on the element on the page that contains the data you want to extract. PullNode builder will automatically detect similar elements on the page and suggest them to you (highlighted in yellow).
You can click on a suggested element to exclude it and have PullNode re-analyze. You may also click multiple elements to include them in the same property.
Once you have selected the desired elements, click "Save" on the selector bar to add the property to your scraper.
Add as many properties as you need to extract all the data you want from the website.

Additional options
 Choose the next page element and how many pages to automatically paginate through the website.
Choose the next page element and how many pages to automatically paginate through the website.
 Choose how many times the page should be scrolled to load all the data.
Choose how many times the page should be scrolled to load all the data.
 Enable cookies to allow the scraper to access websites that require authentication.
Enable cookies to allow the scraper to access websites that require authentication.
Saving the scraper
Once you have added all the properties you need, click "Save" on the Builder bar to save the scraper. You will then be taken to PullNode's dashboard (or login page first), where you can see your scraper and run it.